こんにちは。セルネッツの竹本です。
今回は「システム開発入力チェック」というテーマで解説をします。
特定の開発言語に特化した内容ではありませんので、プログラミングを勉強中のかたはぜひ最後までご覧ください。
なぜこのテーマを選んだのか。
システム開発ではデータの精度を高めることに非常に重要な役割があります。
これはソフトウェアの品質との関連性が大きいことが理由になります。
たとえばユーザーフォームにデータを投入するとき、データベースにデータを投入する際に必要な入力チェックをきちんとすることでデータベース内に書き込まれる情報の精度が高まり、信頼性が高まる状態になります。
そういった意味でも入力チェックが非常に重要になります。
入力チェックとは、入力データの妥当性をチェックするということです。
妥当性のないデータであったり、許容できないような不正なデータであればその段階で不正の内容を伝えて正しい値を入れていただくように促します。
また、データベース投入の際の入り口になるので、データの投入が行われるときにデータをきちんと精査してあげることで信頼性が高まります。
入力チェックの種類についてお話をします。
存在チェック、妥当性チェック、属性のチェック。
また入力フォームからデータを登録するときに必須なのか任意なのかというところもあります。
このあたりはお客様との打ち合わせによって、厳しすぎず緩すぎず、妥当な範囲を定めていくことが重要になります。
ポイントですが、入力チェックは前提条件を先に定めることが重要になります。
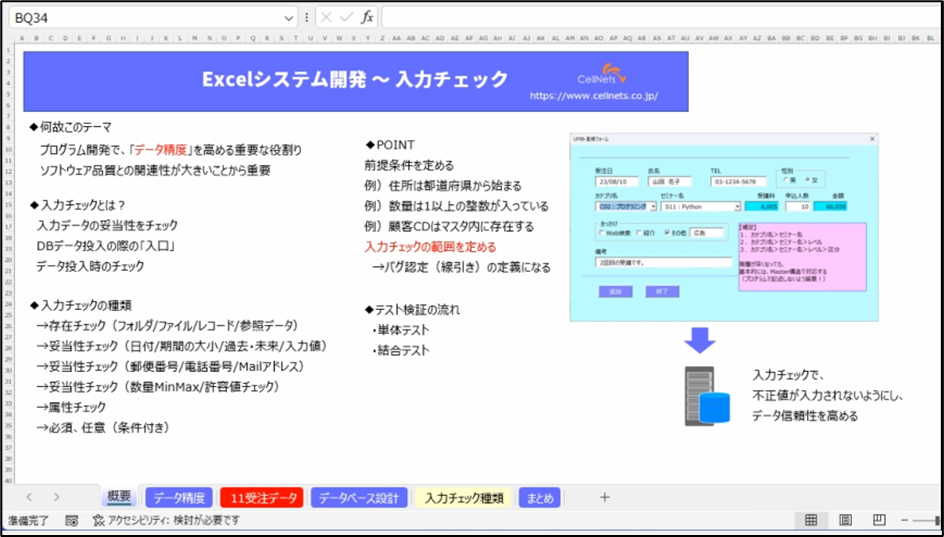
受注データの登録フォームがあったとします。
住所は都道府県から始まる。数量には1以上の整数が入っている。顧客コードはマスター内に存在する。
たとえばこの3つが大前提で、「これはそういうふうなデータになって流れてきます」ということであれば、「A列の顧客コードは顧客マスターに必ず存在する。存在しないことはありえない」ということであれば存在チェックをかける必要はなくなります。
数量は「1以上の整数」ということは「小数点付きはない」ということになりますし、「0と空欄はない」ということが言えるので、数量に関するチェックは上限のチェックなどは必要になるかもしれませんが、チェックの数が減ります。
都道府県に関して、9列の値には実在する都道府県が必ず入っていて、誤りや空欄などはないということであればチェックが不要になるので、前提条件によって範囲を定めることでバグ認定の定義になります。そういう意味でも重要です。
バグ認定とはデータ依存によって発生した不具合・障害に関して、前提外のデータが入ってきたことによって起きた障害であれば、バグではなく、ソフトウェアの不具合でもなく、データ依存型の不具合です。なぜ不具合のデータが発生したのかによって先の流れが変わってきます。
いずれにしても入力チェックの範囲を定めるためには前提条件を定めることが重要になります。
テスト検証の流れです。
「このソフトウェアは十分なテストが行われました」と口頭でお伝えしても具体的にどんなテストをしたのかを立証できる状態にしないといけないので、テスト検証は非常に重要になります。
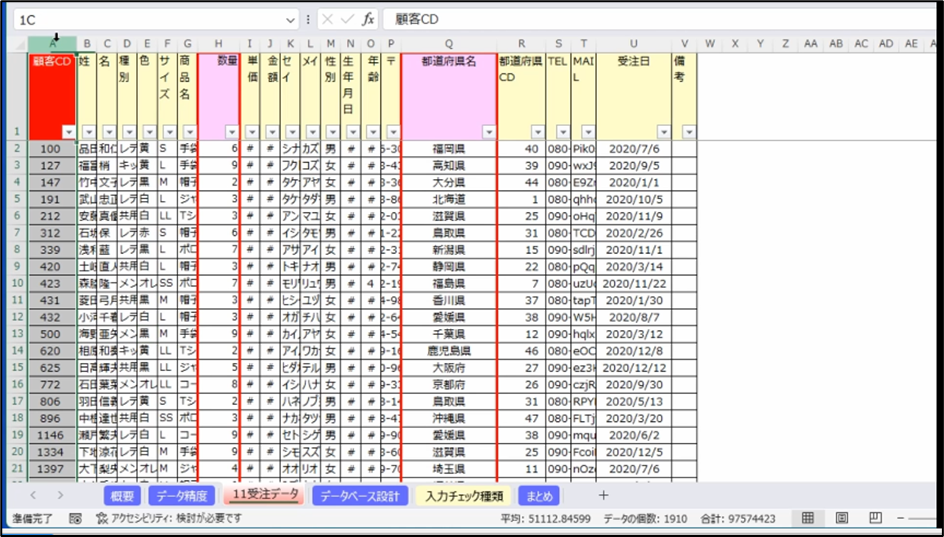
データの流れ方の図を書いてみました。
大規模システムの場合はこういったプログラムがたくさん存在します。
この例では佐藤さんがプログラムID、CN11番を担当することになり、田中さんが21番、佐藤さんが31番です。
たとえば佐藤さんのCN31番のプログラムに不具合が生じたとき、原因がデータの不正値が混在していたことによる障害だったとします。
佐藤さんのプログラムはDとEを入力として使ってFを作り出していますが、Dに不正値が入っていないはずなのに入っていたとすれば、佐藤さんのプログラムが悪いわけではなく、Dを作った田中さんのプログラムになります。
田中さんのプログラムはAダッシュとBを入力としてDを作っているので、この段階で不正なデータが作成されてしまったがゆえにそのデータが佐藤さんに渡ったということになります。
田中さんにしてみれば「そもそもAダッシュの中に不正なデータが入っていたことが原因だった、だからDにそういうものが入ってきた」となります。
もうひとつ遡ると、Aダッシュは佐藤さんのプログラムID、CN11のプログラムが作っています。
佐藤さんはA・B・Cというファイル、そしてキーボードからの手入力です。
この4つの入力のモードが元になってAダッシュが作られています。これはAを更新しているようなイメージになります。
ここにあってはならないデータの状態が起きていたということになると、ファイルの中にそういうものが入っていたのか、手入力するときのチェックが甘かったのかとなります。
いずれにしても不具合が発覚したのがこのタイミングだとすると、不具合の原因がわかったときにリカバリーという復旧作業を強いられるので、データの精度は非常に重要になります。
データの流れですが、複数システムによる連携ということで、佐藤さんが自分の1本のプログラムの単体テストをします。
上流から下流まですべて流してテストをするのが結合テストです。大きく「単体」と「結合」という呼び方をしています。入力チェックが重要になってくるのはこういったことが理由になります。
入力チェックの種類もテスト設計のところで本当はがっつり決めていきます。
テスト設計、テスト仕様書に基づいた入力チェックを行うことにはなるものの、ドキュメント制作は非常にコストがかさむので、経験値でそのあたりを網羅していくケースもExcelの開発では珍しくありません。
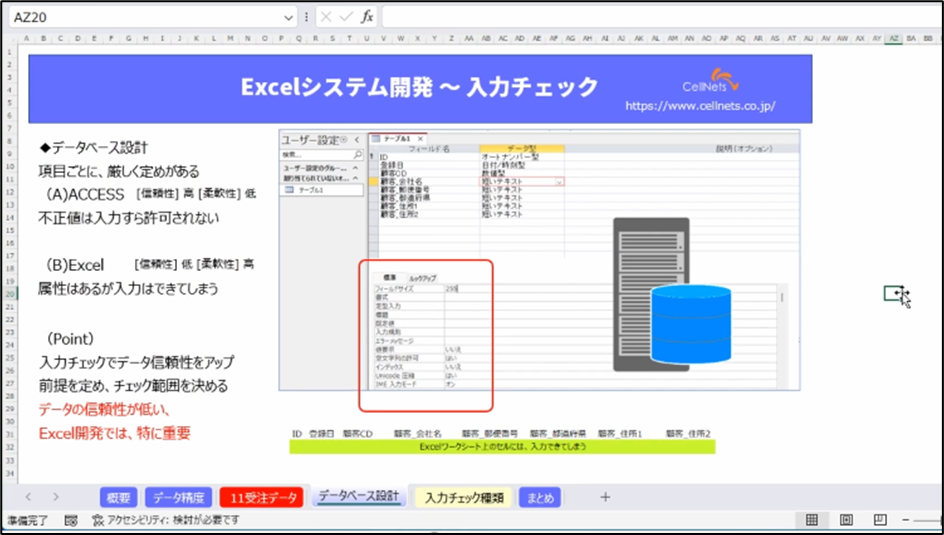
データベースの設計です。
たとえばAccessはデータベースですが、テーブル定義、テーブル設計の話になります。
Accessの場合は登録日が日付型だとか、顧客コードが数値型だとか、文字にすることもできます。会社名・郵便番号・都道府県・住所の1、2。これは住所を3分割しているのですが、これも設計の考え方です。
フィールドサイズも規定値は255になりますが、書式、定型の入力、規定値入力規則、エラーメッセージ。このあたりを細かく定義の設定をしていきます。データベースなので定義の設定が必要になるのです。
一方でExcelの場合はここまでのことはやりません。できません。表計算ソフトなので主に縦型横型というようなアプリケーションになります。
Excel開発の場合になにが重要になってくるのかというと、Accessの場合は不正値は入力すらできないんです。
大量なExcelのデータをAccessにインポートしようとすると不正なデータレコードがあれば取り込むことができなくなるので、不正値は入ることさえできないということで信頼性は高いですが、柔軟性はそのぶん低くなります。
Excelの場合はそれに比べると、属性はある程度、数値・文字・日付は書式設定であるものの、日付書式にしたとしても文字も入るし、数値書式にしても数値ではない記号なども入ります。
ということで、柔軟性は高くなるものの信頼性は低くなります。
よく「Excelで開発したほうが良いでしょうか?Accessで開発したほうが良いでしょうか?」と質問されることがあるのですが、大量のデータを大人数で信頼性の高いデータベースを使いながらやっていく必要があるものはExcelではダメです。
そうでないケース、利用人数が少なかったり、データが数万件だったりであればAccessデータベースを使うまでもなく開発ができてしまいます。
ポイントとしては入力チェックでデータの信頼性をアップするということです。
そして前提を定めることでチェック範囲を決めるということです。
Excelの開発では「データベースからのデータを取り出してなにかを」ということではないので、お客様が長年使ってきた、手入力をたくさんしてきたデータを入力として使うことが多いので、不具合が出ないようにするためには信頼性は低くなるという前提でチェックをしないといけません。
この部分がデータベースから取り出したデータを使うシステム開発と、Excelの生データを使う開発とで決定的に違いますので、入力チェックはそういう意味で非常に重要になります。
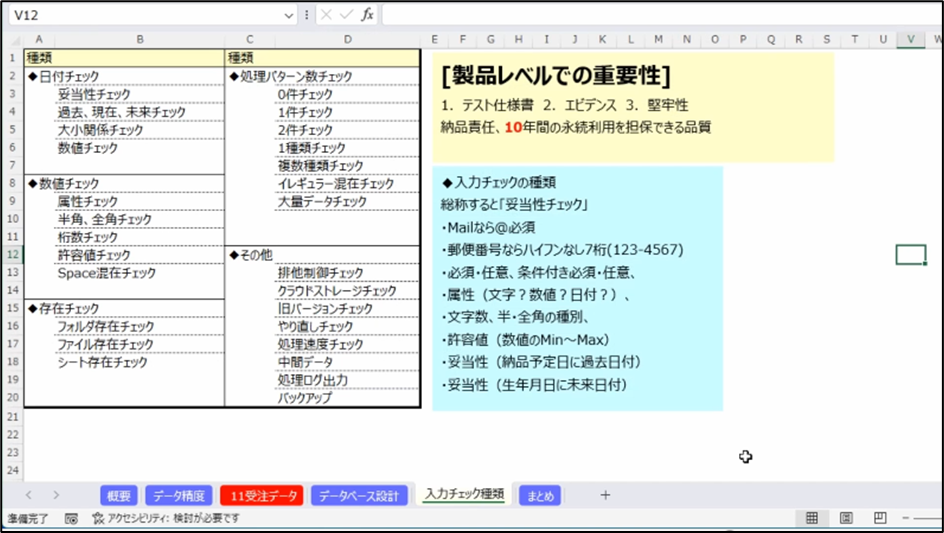
最後、入力チェックの種類です。これ以外にもたくさんあるのですが、細かいところをカテゴリーで分けてみました。
まず日付のチェックは妥当性チェックと呼んでいますが、現在・過去・未来、この妥当性です。たとえば納品予定日は未来の日付なので、納品予定日が過去ではおかしいですよね。生年月日が未来になることもおかしい、受注日が未来になることもおかしいですよね。
ということで、「過去だとエラー」「未来だとエラー」という妥当性をチェックするケースが多いです。
それから大小チェック、日付の期間です。いつからいつまで。from toが逆になっていたらエラー警告しないといけませんし、日付に見えて文字だったりすると、それは日付に見えて日付とはみなされないので、日付チェック・数値チェックという属性のチェックが必要になります。
数値の中でも半角なら数値、全角の数字は文字です。
桁数が少なすぎてもダメ、多すぎてもダメ、固定の桁数しかダメなケースもあります。許容値です。
特定の数量以上は受注できないものであれば上限や下限が定まったりするので、そういったところのチェックが細かいレベルで必要です。
それから王道です、存在チェック。
そもそもフォルダが存在していなければエラーになる作り方だったり、フォルダがあってもファイルがなければエラー。ファイルがあっても正しいファイルでなければエラー。正しいファイルの中にシートはあったけれどもシートの名前が正しくなければエラー。どこまでチェックをかけるのかというのは前提がどこまで定められるかのバランスになります。
処理パターンです。処理するデータが0件だった場合は処理ができないというケースだったり、1件なのか2件なのか大量なのか。それから種類数をチェックすることもあります。
イレギュラーの混在チェック。混在するべきでないデータが入っているかどうか。
たとえば機種依存のケースがありますが、機種依存文字の存在チェックはなにをもって機種依存なのかというと、機種に依存するのでチェックができなかったりしますが、イレギュラーな混在チェックも考えないといけません。
それから必ずやらないといけない大量データチェック。テストは数十件でやっていて正常動作でも、実際は数万件が日常だったりすると、それが原因で速度が遅くなったりして「大量データのチェックをしていませんよね」となるので、そこのチェックも必要になります。
いろいろありますが、このあたりはシステム開発、プログラミング開発ということで、VBAに特化した話ではなくシステム開発ということで、必ずこの考え方で取り組む必要があるので大事な工程だと考えていただければと思います。
製品レベルでの重要性です。
テスト仕様書の中でデータはお客様から支給されるのか、自分たちが作るのか、どういうケースをテストするのかを定めたうえでプログラミングでチェックを開発に反映していきますが、テスト仕様書に基づいた結果を署名に残すのがエビデンス、証拠です。
「こういうテストをこういうデータを使って検証したらOKでした」ということで、このエビデンスを求められるケースもたくさんあります。
堅牢性ということですが、実効時エラーが発生しない、なにをやっても大丈夫というような、実行時エラーがすぐに発生しない、すぐにというか発生しちゃいけないんです。
これは製品レベルでは求められることになります。
自分自身の業務の効率化であればお金をいただいて納めるものではないので、このあたりは緩くても大丈夫だと思いますが、製品として提供する側のお仕事をされるかたは10年サポートが暗黙の了解になるので、これから独立をしようと考えているかたは「正常動作をすれば良い」ではなく、動作を保証し続けられるような拡張性のある作り方をしていく必要があります。
そのため、入力チェックに対する考え方は多くの引き出しを持って取り組む必要があります。経験も必要ですが、そういったところを勉強していく必要があります。
最後になりますが、入力チェックの種類に関してはメールだったら「@」が必要ですし、ハイフンなら郵便番号の「3桁-4桁」という構造になりますし、前提条件を定めたうえで必要なチェックをするようにしましょう。
解説は以上となります。
少しでも参考になったかたはぜひチャンネル登録・高評価をお願いします。
Excel中心の業務効率化やシステム導入についてお困りのかたは無料オンライン相談も受け付けていますので詳しくは概要欄をご覧ください。
動画は毎週金曜日の夜9時に投稿しています。ご視聴ありがとうございました。
タケモ塾では、今後も皆さんのVBA学習に役立つコンテンツを作成してまいります。
ブログ記事、Youtubeチャンネルのご質問・ご感想・ご要望などお気軽にお問合せください。
お問合せはこちらから ✉
タケモ塾運営:株式会社セルネッツ

